I’m back with another little script that might be pretty handy for those who need to work on the same material in different CAT tools, or for translation agencies who use OmegaT as their main CAT application but farm out the work to translators using their CAT tools of choice. As a matter of fact, the script was requested by translation agency Velior for this very reason.
When the script is invoked, it writes out a file named PROJECTNAME.xlf (PROJECTNAME is the actual name of the project, not this loudly yelled word, of course), and the file is located in script_output subfolder of the current project. It exports both translated (they get “final” state in the resultant XLF file) and untranslated segments, and for untranslated segments the source is copied to the target, and such segments get “needs-translation” state. OmegaT segmentation and tags are preserved. Tags get enveloped in <ph id=”x”> and </ph>, so that they are treated as tags in other CAT tools.
Here is the link where you can download the ready-to-use (albeit still BETA) version:
To get the translation back to OmegaT once the file has been processed in another CAT tool, it’s advised to use Okapi Framework (Rainbow for GUI/Tikal for command line). To get 100% transferability the pipeline in Okapi should include TMX export and Inline codes removal (remove marker, keep content). The script can write out a .rnb file (enabled by default) that can be opened in Rainbow.
Here’s how conversion to TMX is done in Rainbow:
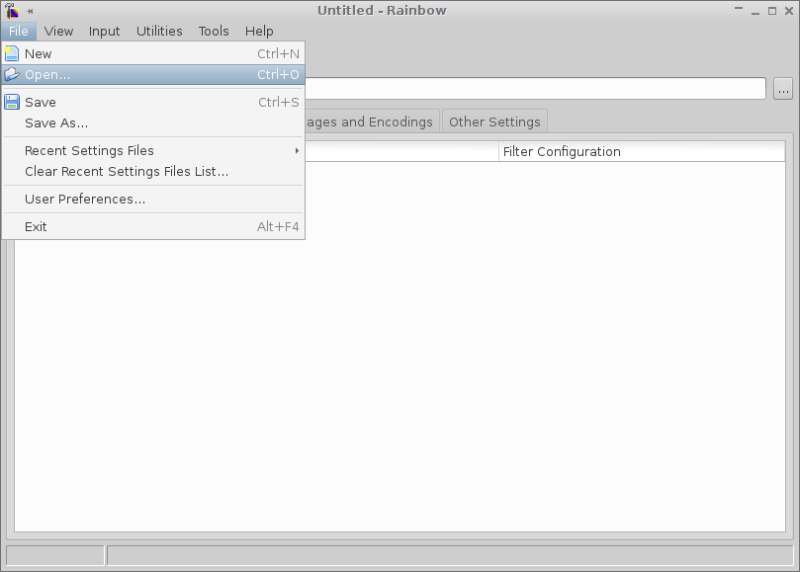
- Start Rainbow.
- Open the settings .rnb file created by the script (located in
script_outputsubfolder of the project).
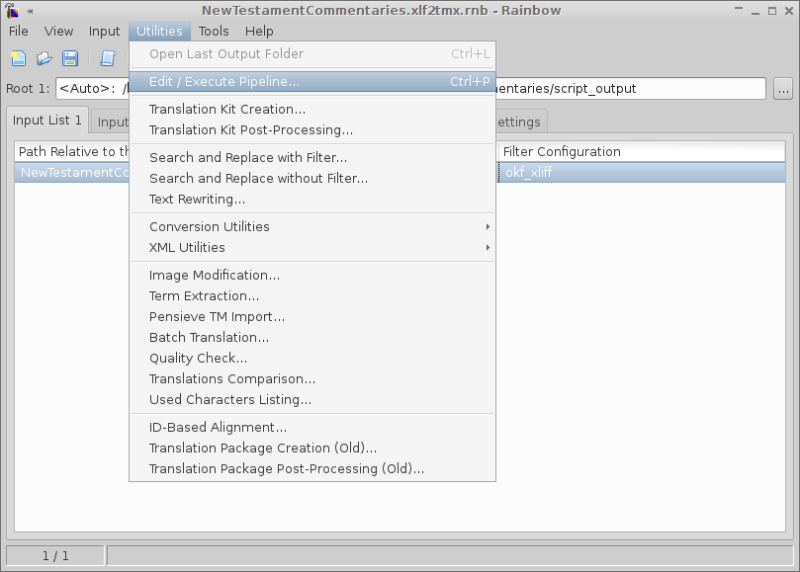
- Drag the
PROJECTNAME.xlfinto the first tab of Rainbow window. - Go to Utilities → Edit/Execute Pipeline and press Execute button in the window. Several settings might need to be tweaked for TMX conversion step (see screenshot).
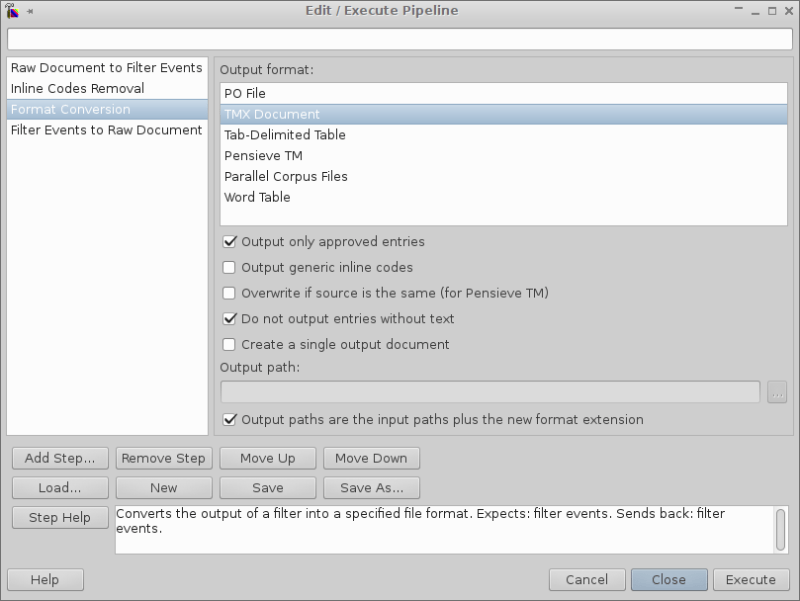
- The TMX file will be created in the same folder where the XLF file was.
It has been tested with Virtaal, Transolution Xliff Editor, SDL Trados Studio 2011, Kilgray MemoQ 2013, and ATRIL Déjà Vu X2. These programs can create TMX files containing the translation that is supposedly the same as in the XLF file. But when those TMX’s are used back in OmegaT, there are always issues with tags. To get “perfect” matches, the XLF itself has to be converted as described above.
The script is in BETA stage. It means that whatever happens to your data, hardware or mental state, I didn’t do it! More tests are always appreciated. Bug reports and feature requests can be left here as comments or filed at SourceForge bug tracker (make sure you’re filing them in my project, not in the project for OmegaT, as I don’t want to be hated by OmegaT developers).
UPDATE
Converting XLF to TMX to be used back in OmegaT now can be automated. See this post for details.
But as of now,
GOOD LUCK

Great info. Thanks!
Hi there, Kos. Thank you for this wondeful script, it come in very useful to outsource part of a project in OmegaT to linguistis who use OLT. However, I found a small glitch. The original XLIFF files have something like: <b>sometext</b> and in your merged XLIFF I get: <bzzzsmall>/bzzz. This is probably due to the specific nature of my XLIFF files, not your script, but not knowing for sure I wanted to share it with you, in case you have any tips. Thanks!
No, that has very little to do with the particularities of your files. It has everything to do with me being a lousy coder. I’ll see if I can do anything, I just don’t know when.
Thanks for your reply.
Sorry, HTML tags got interpreted. Let me try again: I have <b>sometext</b> and in your merged XLIFF I get: <ph id=”1″><bzzzsometext></ph>/bzzz
Hi, I made small fixes as described in the Yahoo Group to make it run in the latest versions of OmegaT (tested on 3.).
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
xliff_export.groovy
hosted with ❤ by GitHub
Hi Kos. Some more feedback: I tried your script today again to export a one-file OmegaT project as XLIFF. I got this error in the scripting console:
The script “C:\Users\souto\AppData\Roaming\OmegaT\scripts\write_xliff.groovy” is running…
An error occurred
javax.script.ScriptException: javax.script.ScriptException: groovy.lang.MissingMethodException: No signature of method: static org.omegat.util.StaticUtils.makeValidXML() is applicable for argument types: (String) values: [<x1/>]
Indeed, my first segment has `<x1/>`. I am using the OpenXML filter.
Thanks for the reply. I’ll try to make sure this script works in the latest version of OmegaT, and will report back here.
Thanks a lot for sharing this amazing script! I am totally new to Omegat, so my question is how to invoke write_xliff.groovy?
I’ve figured it out. Open an project in Omegat and then select Script under Tools menu.