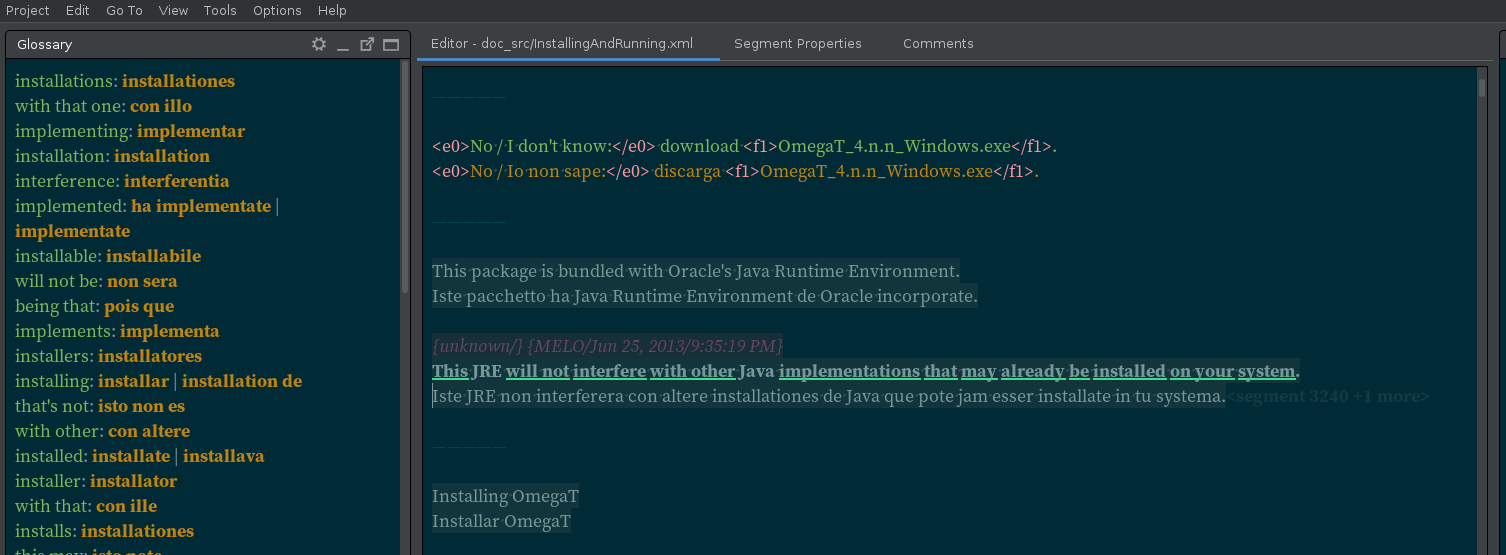
As announced previously, an alternative glossary pane layout was made available as a plugin. The newest update (v.1.1.0) now includes 4 variants of that compact layout:
- 1A
source: target [comment] | target [comment] | [comment](separator|is styled as normal text — the same as in the original version)
- 1B
source: target [comment] | target [comment] | [comment](separator|is styled as target terms)
- 2A
source: target (comment), target (comment), (comment)(separator,is styled as normal text)
- 2B
source: target (comment), target (comment), (comment)(separator,is styled as target terms)
Once again, here’s the project itself, and here is where you can download the compiled version. If you run OmegaT on Java8, make sure to download the right build. On Java11 it doesn’t matter which build is used.
Comments, bug reports, complains, latest gossips and donations are always welcome.
Take care and good luck!