
The earlier version of this script was described in this article. Here I’m announcing the update to the script which makes it possible to include:
- Segment ID for each segment (applicable only for some file types)
- Translator’s ID of the segment’s translation creator
- Translator’s ID of the segment’s translation editor
- Segment notes
- Visual marks to show segments’ uniqueness or repetitions (grayish background, marks
1or+in the dedicated column: for the first occurrence, or further instances of the repeated segment, respectfully) - Visual marks for alternative translations (different font color, mark
awith a different background in the dedicated column) - Visual marks for untranslated segments (mark
NTin the dedicated column) - Visual marks for paragraph boundaries (upper border over the source and target text which visually groups the text belonging to the same paragraph)
All of the above features are optional, though they are on by default. To disable or change them, editing the script is required, but all those lines are very easy to understand, they have comments, and are placed almost in the very beginning of the script:
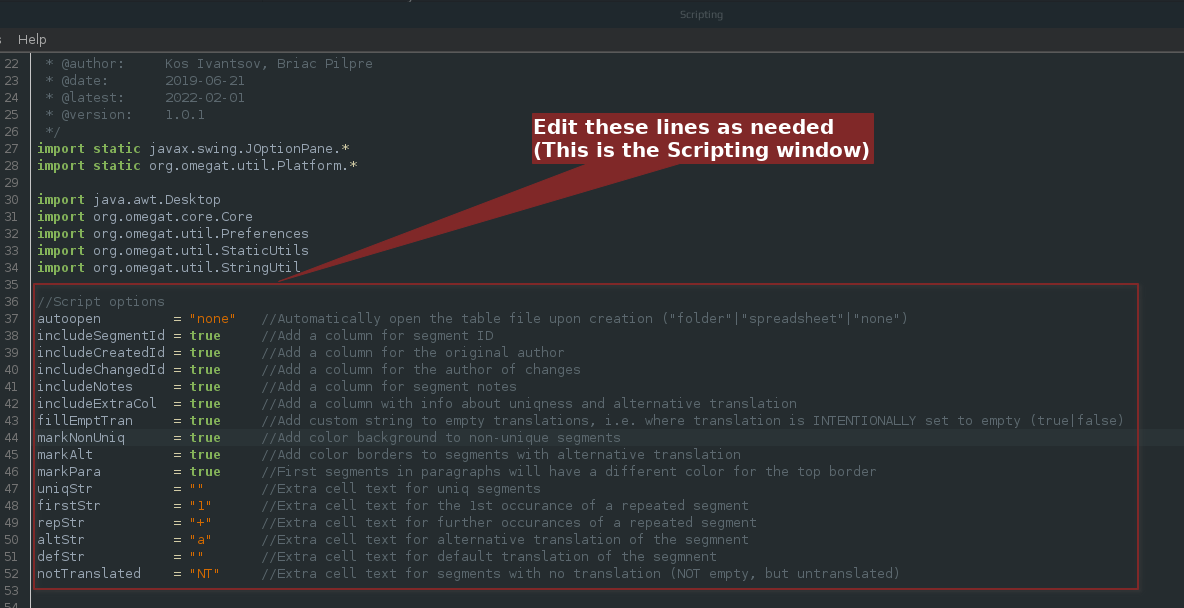
Unlike the earlier version, the script produces the tabular output:
| Segment # | Source Text | Target Text | Uniq/Al | Segment ID | Creator | Changer | Note |
|---|---|---|---|---|---|---|---|
The script can be downloaded from
SF.net repository
GitHub repository
To learn how to install and use OmegaT scripts, see this quick guide.
Comments, suggestions, complaints, and donations are always welcome!
Happy spreadsheeting!
