Over the years of my daily use of OmegaT (I started using it back in 2009), I helped quite a few translators to make their first steps with the program. The funny thing is that almost every time a new person tries to learn the program, we change some of the same defaults to make it more usable and comfortable. So I thought it might be a good idea to collect those few initial setup changes here as a small series of posts so that anyone could refer to them at any point.
The first thing I always have new users change is the Editor behavior.
Below is a screenshot with the default Editor settings. Green markings are the options to be changed.
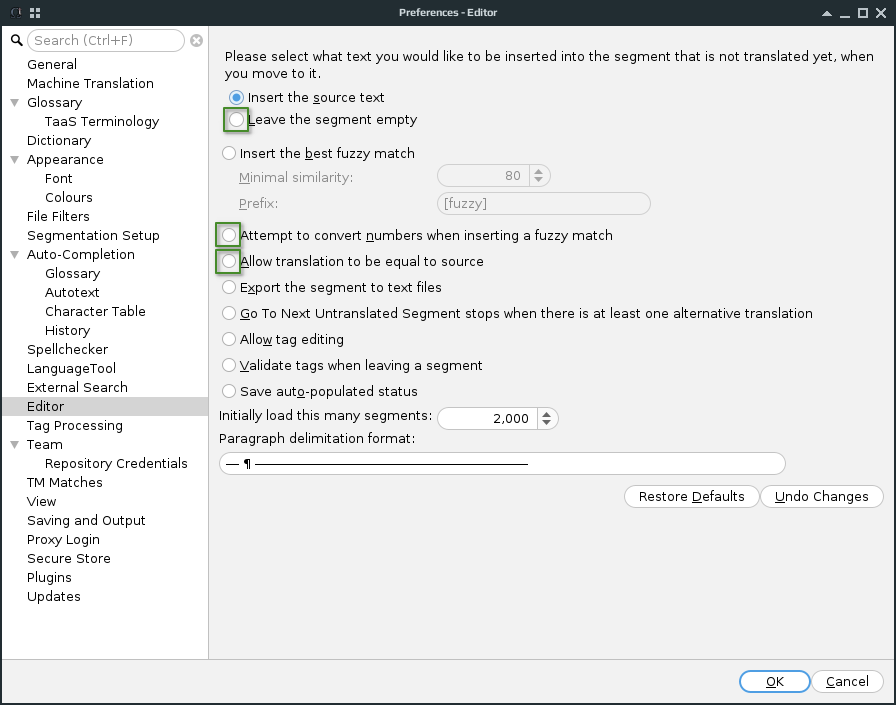
Leave the segment empty is a must when you’re working with languages that use different scripts or are just very different, and your translation involves actual language and not just digits and proper names. The default setting is really, really annoying.
I don’t recommend enabling Insert the best fuzzy match simply on the assumption that things like that should be the translator’s decision, even if it’s a perfect match. I guess some redundancy in carefulness is better than being a bit short on it.
Attempt to convert numbers… is a very neat feature that somewhat flies in the face of the above-mentioned assumption. It works when it works, and works pretty nice, but when it doesn’t, it’s quite frustrating. In any case, I find it easier to check only the numbers in the inserted match than the whole match, therefore I recommend having it on.
If Allow translation to be equal to source isn’t enabled, segments where the translation should be identical to the original text, even if the translation was previously typed/inserted, will show as untranslated next time the project is loaded because they are not written into the project’s TM unless they were specifically registered as identical translations (Edit → Register Identical Translation). To prevent it, enable this option. Maybe it’s not a critical one, but if you, too, like me, like to glance at the stats bar in the lower right corner to see if the file/project is completely translated, this one is rather helpful. Otherwise, you might need to jump around “untranslated” segments to make sure they are the ones where the original text should be used in the translation.
I also change the Paragraph delimitation format to something shorter (after a few tries I ended up using 5 m-dashes: —————), but it’s not really that important for productivity.
With the changes above the translator has more control over the way OmegaT behaves. In the next post of this small series, I’ll share a few ideas about a better setup for the Fuzzy matches area.

Good tips. I agree that OmegaT’s factory settings are not very much in line with modern CAT tool best practices.